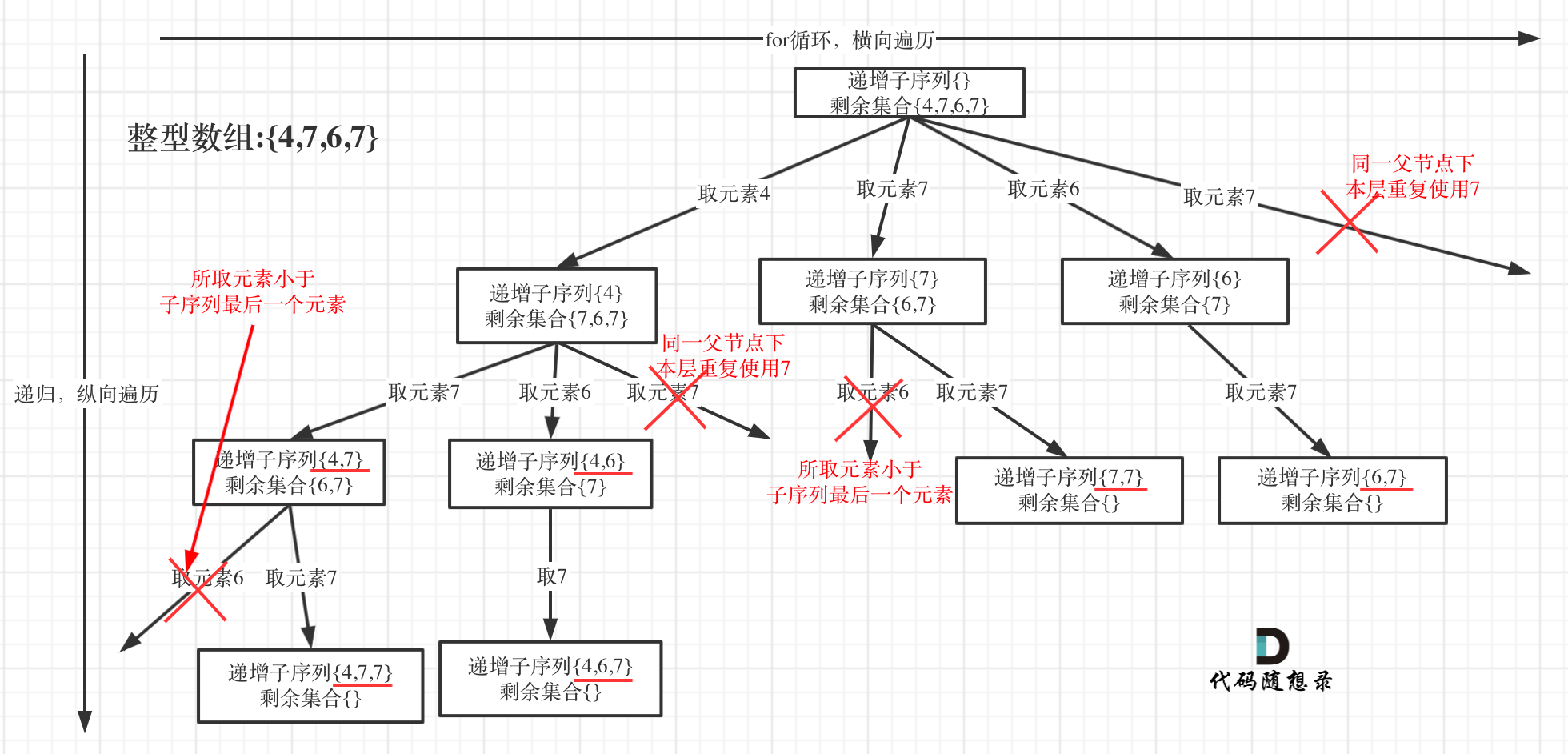
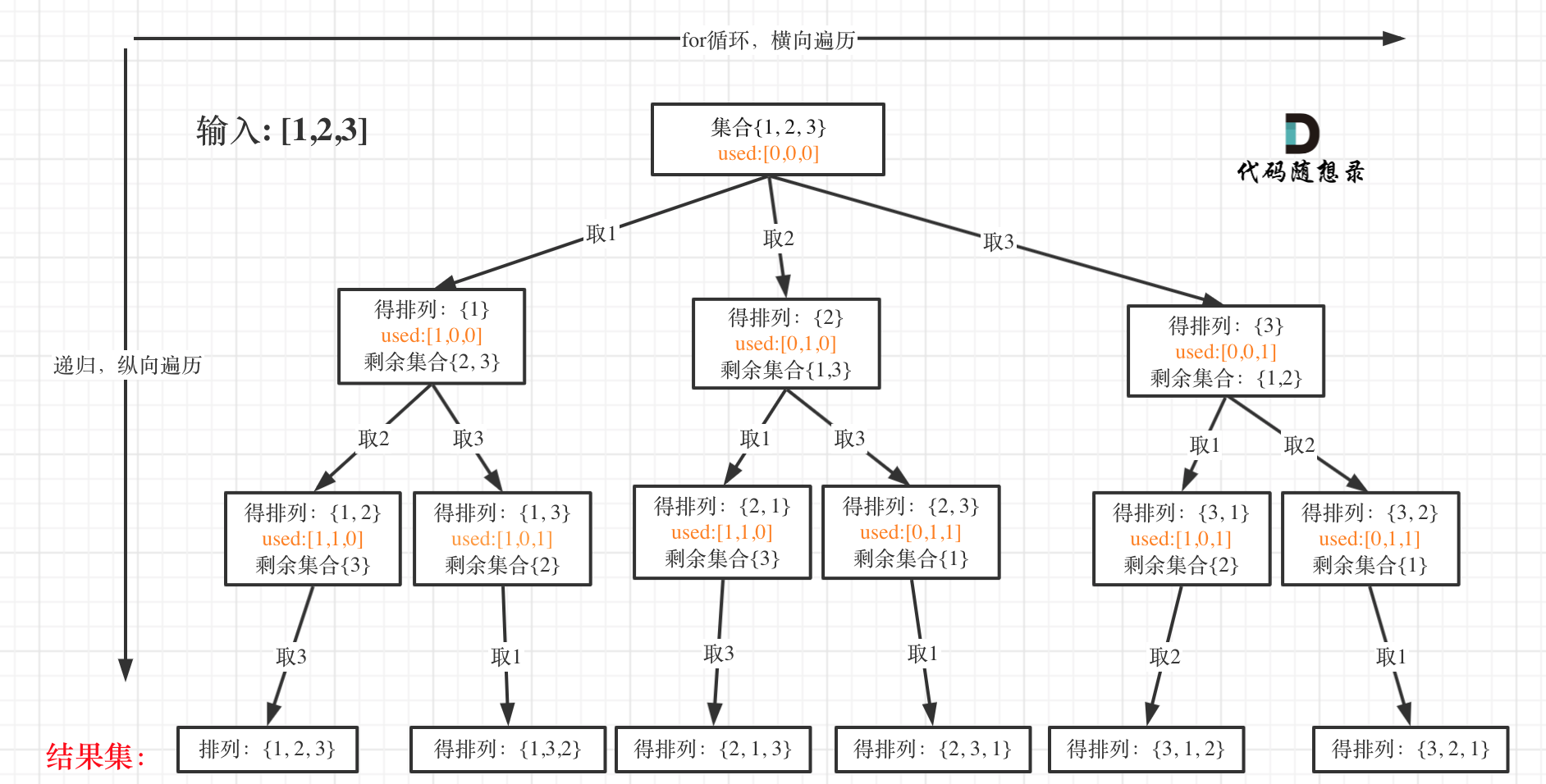
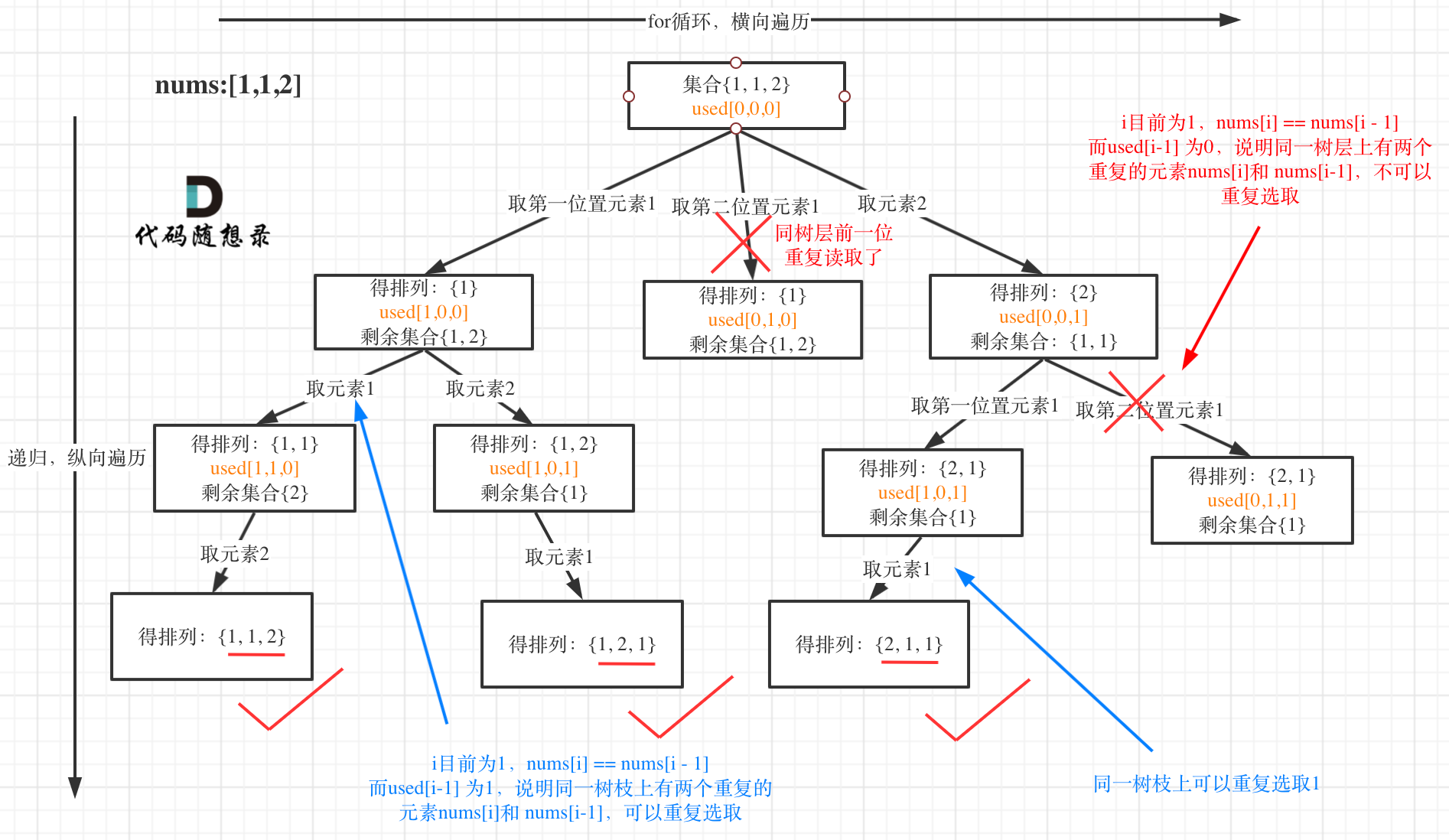
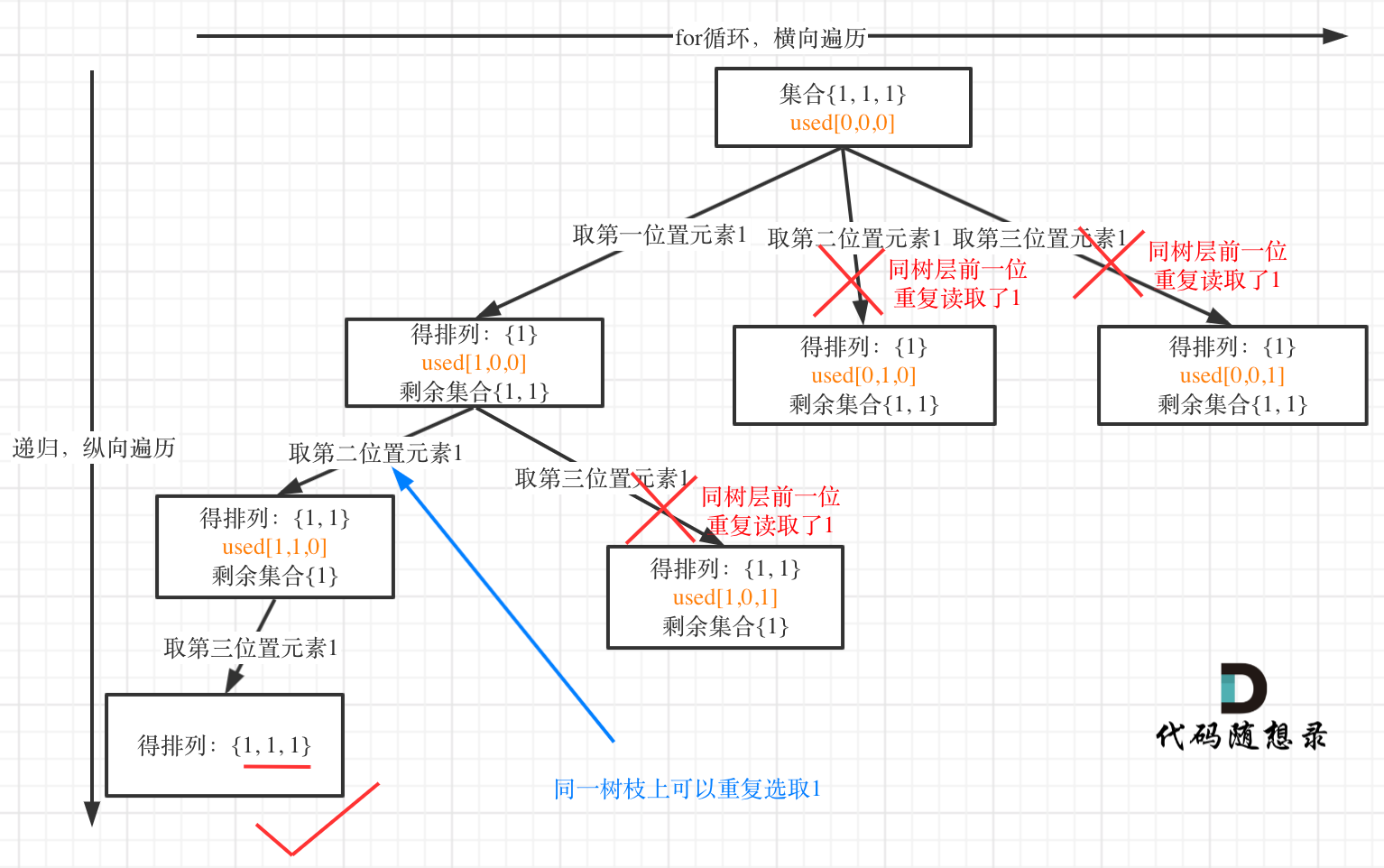
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows; using System.Windows.Controls; using System.Windows.Data; using System.Windows.Documents; using System.Windows.Input; using System.Windows.Media; using System.Windows.Media.Imaging; using System.Windows.Navigation; using System.Windows.Shapes;
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows.Forms;
namespaceWinFormHelloWorld { publicpartialclassForm1 : Form { publicForm1() { InitializeComponent(); }
是ASP.NET Web Forms技术的升级版。其特点是代码解耦合,易于维护。创建项目同ASP.NET Web Forms,但是要点击empty,勾选MVC。选择controllers-add-controller,选择MVC 5 Controller - Empty,点击add,然后输入其名称为HomeController,然后add。此时生成了HomeController.cs的样板代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.Web.Mvc;
点击运行,会启动wcf test client的工具。wcf是最特殊的服务,只有纯粹的数据交互,没有前端,因此需要用到这个测试工具。双击其中的SayHello(),点击Invoke,就会调用SayHello函数,该函数会返回一个hello world给客户端。我尝试调用,果然在测试界面打印出了hello world。
现在尝试写一个加法器,在IService1.cs中写:
1 2
[OperationContract] doubleAdd(double a, double b);
在Service1.svc.cs中写:
1 2 3 4
publicdoubleAdd(double a, double b) { return a + b; }
// using是将名称空间引用到程序中来 // 名称空间的标记是{} using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks;
Error 1 The type 'System.Windows.Markup.IAddChild' is defined in an assembly that is not referenced. You must add a reference to assembly 'PresentationCore, Version=4.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35'. d:\OneDrive - stu.xjtu.edu.cn\文档\Visual Studio 2013\Projects\ConsoleHelloWorld\ConsoleHelloWorld\Program.cs 10 13 ConsoleHelloWorld
Error 2 The type 'System.Windows.Markup.IQueryAmbient' is defined in an assembly that is not referenced. You must add a reference to assembly 'System.Xaml, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089'. d:\OneDrive - stu.xjtu.edu.cn\文档\Visual Studio 2013\Projects\ConsoleHelloWorld\ConsoleHelloWorld\Program.cs 10 13 ConsoleHelloWorld
Error 2 The type 'System.Windows.DependencyObject' is defined in an assembly that is not referenced. You must add a reference to assembly 'WindowsBase, Version=4.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35'. d:\OneDrive - stu.xjtu.edu.cn\文档\Visual Studio 2013\Projects\ConsoleHelloWorld\ConsoleHelloWorld\Program.cs 10 13 ConsoleHelloWorld
使用MSDN文档。将鼠标移到一个类上,按下快捷键ctrl+shift+F1,就可以跳转到相应的MSDN文档。如果想看该类在哪个分支上,点击左上角的show topic in contents按钮。以Form class为例,其下面的第一句话:Represents a window or dialog box that makes up an application's user interface.,是以一句话概括本类的作用。接着是:
打开sql server 2012 developer version,创建一个样例数据库:AdventureWorksLT2012,打开Tables,再打开SalesLT.Product,打开其前1000行,主要包含ProductID, Name, ProductNumber, Color等数据。
在项目中,右击solution-add-new item-data-ado.net entity data model,将其名字改为AdventureWorksModel.edmx。选择generate from database,然后新建一个和本地数据库AdventureWorksLT2012的连接。然后选择Product表和Address表。此时visual studio就和entity framework一起生成了一些专门用于数据传输的数据模型类。会显示两个数据模型类,分别是Product和Address类。这两个类中,只有属性,没有方法和事件。使用这些类的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13
// 打印产品的Name属性 AdventureWorksLT2012Entities proxy = new AdventureWorksLT2012Entities();
// 快速插入foreach代码的方法是:输入foreach时,当VS2013有所提示时,连续按两下Tab键 foreach(Product p in proxy.Products) { // 输入cw,然后按两下tab键,就会补全为Console.WriteLine Console.WriteLine(p.Name); }
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows; using System.Windows.Controls; using System.Windows.Data; using System.Windows.Documents; using System.Windows.Input; using System.Windows.Media; using System.Windows.Media.Imaging; using System.Windows.Navigation; using System.Windows.Shapes; using System.Windows.Threading;
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks;
namespaceIdentifier { classProgram { staticvoidMain(string[] args) { Calculator c = new Calculator(); int result = c.SumFrom1ToX(100); Console.WriteLine(result); }
}
classCalculator { // 循环写法 publicintSumFrom1ToX(int x) { int result = 0; for (int i = 1; i < x + 1; i++) { result += i; } return result; } } }
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks;
namespaceIdentifier { classProgram { staticvoidMain(string[] args) { Calculator c = new Calculator(); int result = c.SumFrom1ToX(100); Console.WriteLine(result); }
}
classCalculator { // 递归写法 publicintSumFrom1ToX(int x) { if (x == 1) { return1; } else { int result = x + SumFrom1ToX(x - 1); return result; } } } }
using System; using System.Collections.Generic; using System.Linq; using System.Reflection; using System.Text; using System.Threading.Tasks; using System.Windows.Forms;
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows; using System.Windows.Controls; using System.Windows.Data; using System.Windows.Documents; using System.Windows.Input; using System.Windows.Media; using System.Windows.Media.Imaging; using System.Windows.Navigation; using System.Windows.Shapes;
privatevoidButton1_Click(object sender, RoutedEventArgs e) { winList = new List<Window>(); // 往list中加入15000个Window,Window的实例占用的内存较多 for (int i = 0; i < 15000; i++) { Window w = new Window(); winList.Add(w); } }
using System; using System.Collections.Generic; using System.Linq; using System.Reflection; using System.Text; using System.Threading.Tasks; using System.Windows.Forms;
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows.Forms;
namespaceTypeInCSharp { classProgram { staticvoidMain(string[] args) { int a; // 声明变量 a = 100; int b; // 声明变量 b = 200; int c = a + b; // 声明变量 Console.WriteLine(c); } }
int res = 0; int index = s.size() - 1; // 饼干的index
// 优先用大饼干喂胃口大的小孩,因此倒序遍历 for (int i = g.size() - 1; i >= 0; i -- ) { // 饼干成功投喂后,再向前遍历小孩数组,否则不能向前 if (index >= 0 && s[index] >= g[i]) { res ++ ; index -- ; } }
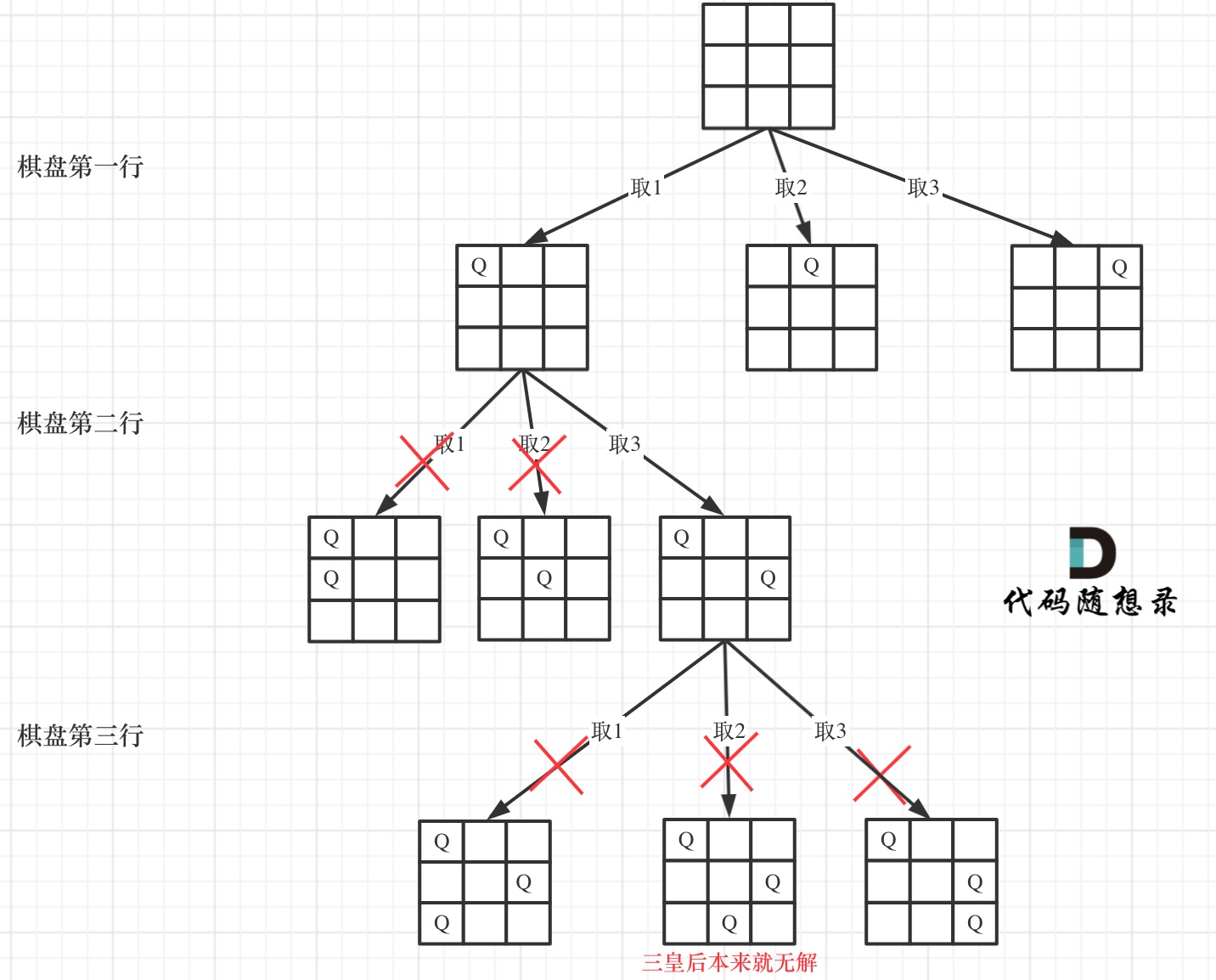
boolisValid(vector<string>& chessboard, int n, int row, int col) { // 同一列中不能有两个皇后 for (int i = 0; i < row; i ++ ) if (chessboard[i][col] == 'Q') returnfalse;
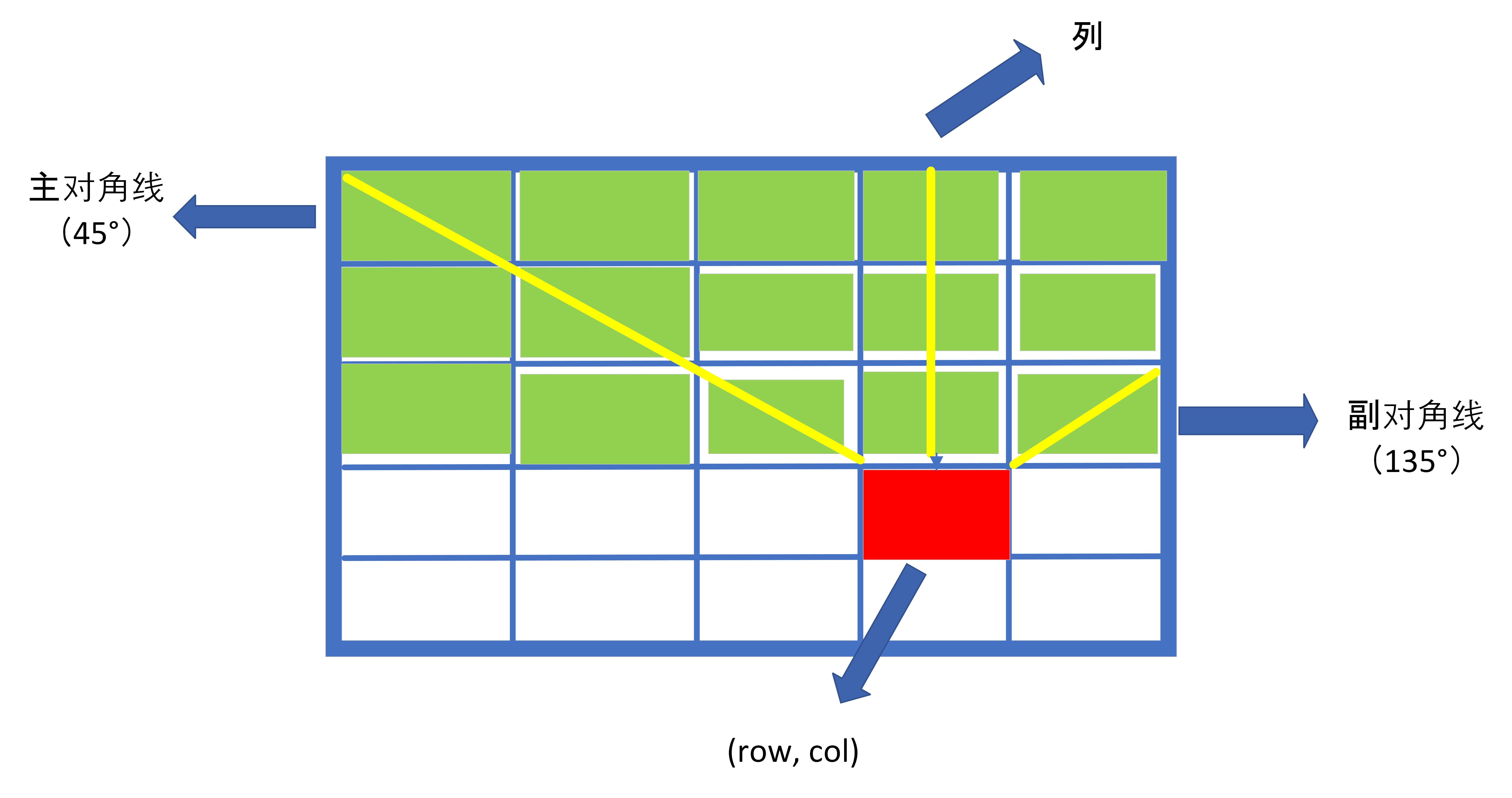
// 主对角线不能有两个皇后 for (int i = row - 1, j = col - 1; i >= 0 && j >= 0; i -- , j -- ) if (chessboard[i][j] == 'Q') returnfalse;
// 副对角线不能有两个皇后 for (int i = row - 1, j = col + 1; i >= 0 && j < n; i -- , j ++ ) if (chessboard[i][j] == 'Q') returnfalse;
returntrue; }
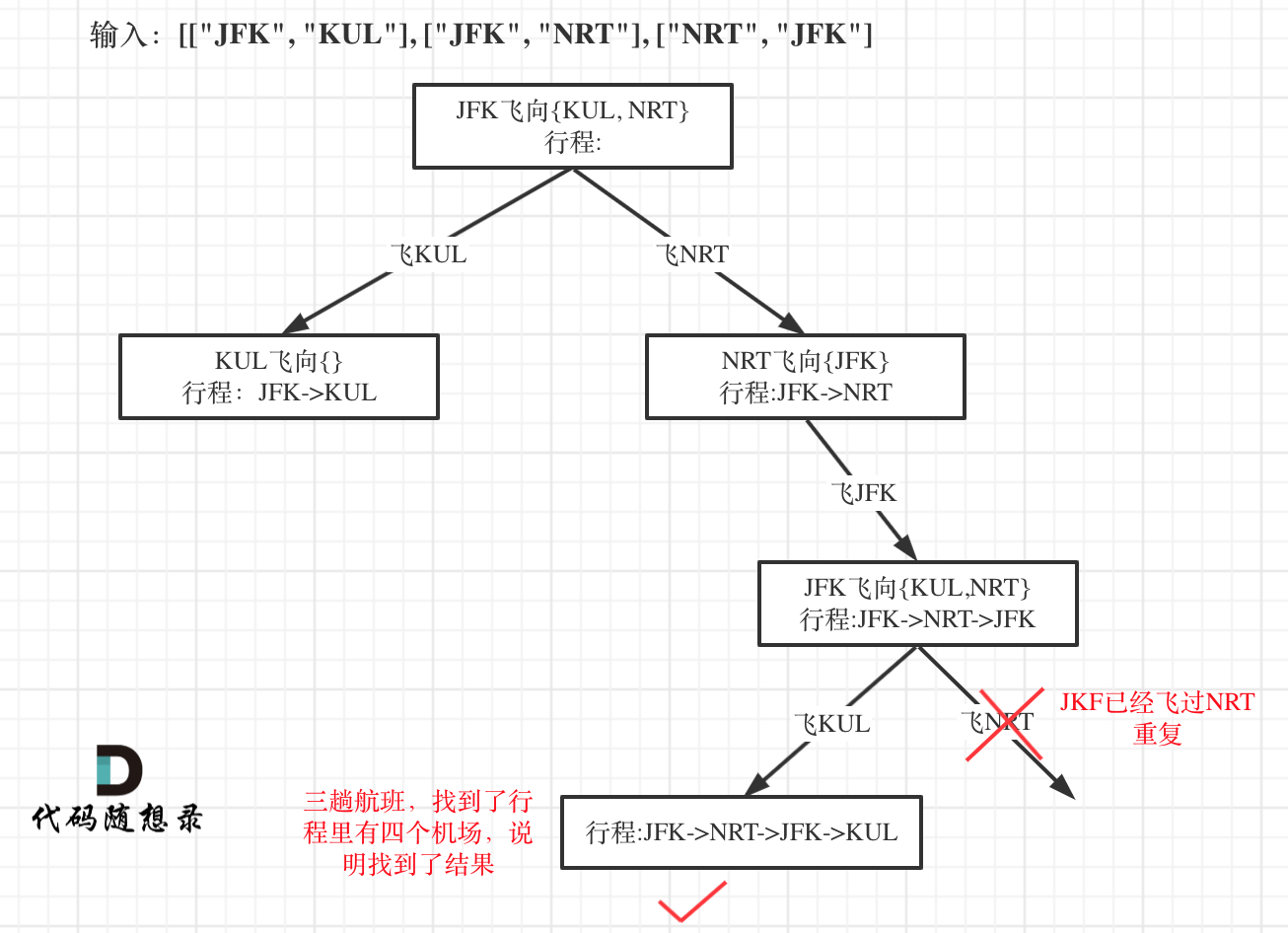
// 传入棋盘,棋盘大小,行数(即递归层数) voidbacktracking(vector<string>& chessboard, int n, int row) { // 终止条件 if (row == n) { res.push_back(chessboard); return; }
// 单层递归逻辑 for (int i = 0; i < n; i ++ ) { // 合法性判断 if (isValid(chessboard, n, row, i)) { // 放皇后 chessboard[row][i] = 'Q'; // 递归 backtracking(chessboard, n, row + 1); // 回溯 chessboard[row][i] = '.'; } } }
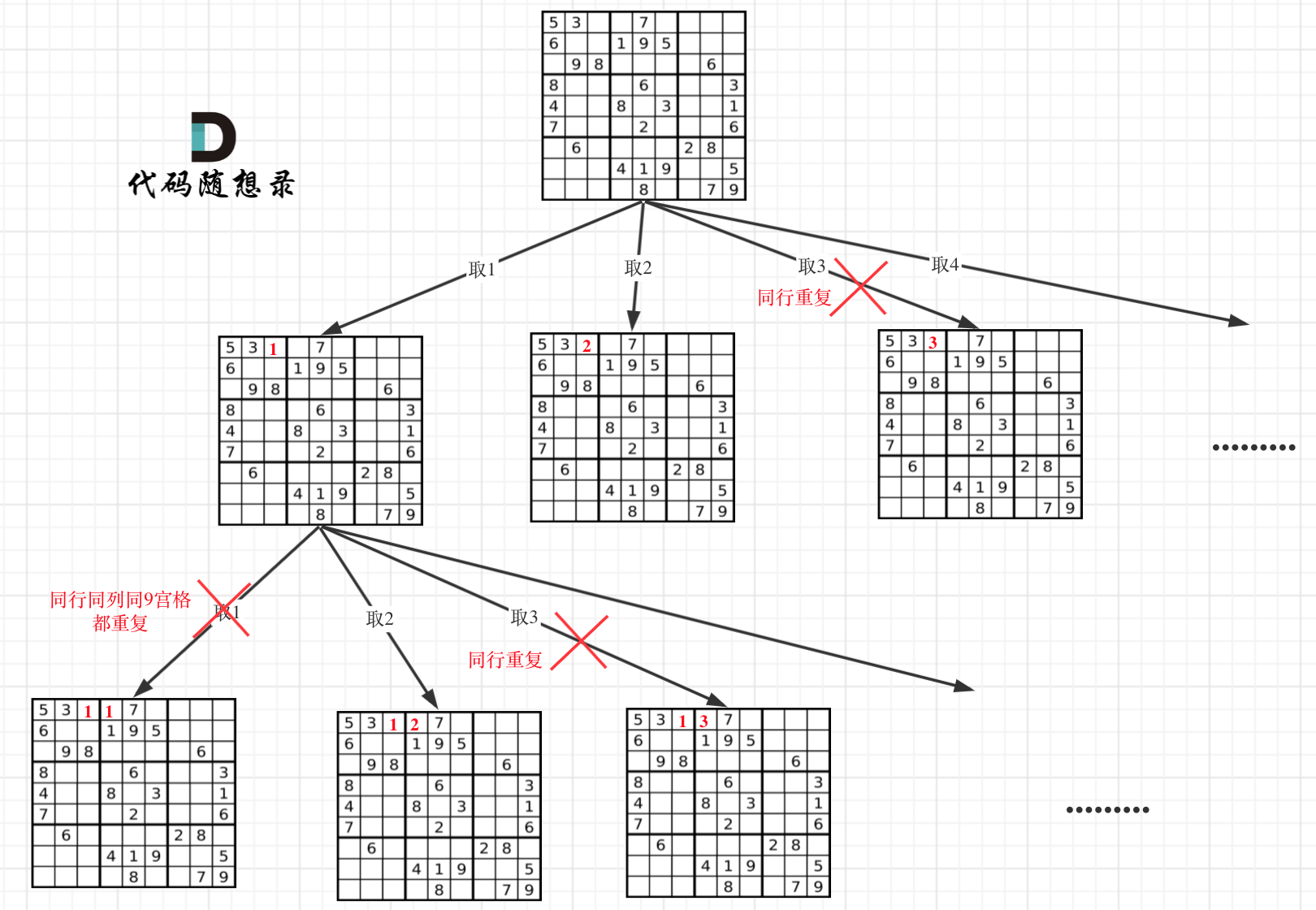
classSolution { public: boolisValid(int i, int j, char k, vector<vector<char>>& board) { // 检查第i行能否放入k for (int j = 0; j < board[0].size(); j ++ ) if (board[i][j] == k) returnfalse;
// 检查第j列能否放入k for (int i = 0; i < board.size(); i ++ ) if (board[i][j] == k) returnfalse; // 检查九宫格能否放入k int starti = i / 3 * 3; int startj = j / 3 * 3; int endi = starti + 2; int endj = startj + 2; for (int i = starti; i <= endi; i ++ ) for (int j = startj; j <= endj; j ++ ) if (board[i][j] == k) returnfalse;
returntrue; }
boolbacktracking(vector<vector<char>>& board) { for (int i = 0; i < board.size(); i ++ ) for (int j = 0; j < board[0].size(); j ++ ) { if (board[i][j] == '.') { // 处理节点 for (char k = '1'; k <= '9'; k ++ ) { if (isValid(i, j, k, board)) { board[i][j] = k; // 递归 bool res = backtracking(board); if (res == true) returntrue; // 回溯 board[i][j] = '.'; } } returnfalse; } } returntrue; }